September 29th, 2024
Diffusion-powered 2D Image -> 3D, Explorable Environment
3rd Place Overall | FIU's Shellhacks Hackathon

Description
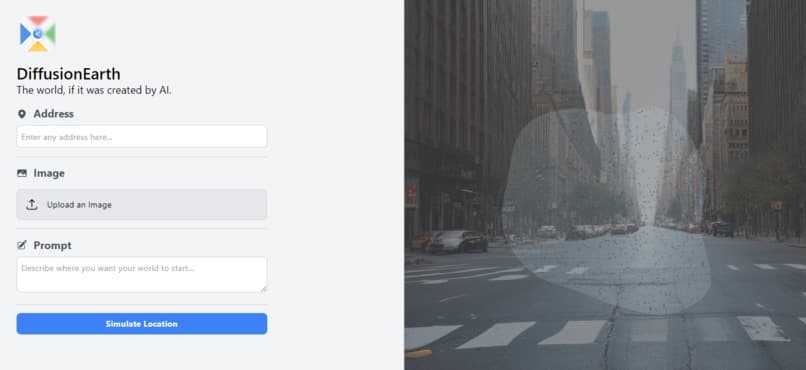
We’ve created a first-of-its-kind 3D environment renderer powered by a combination of diffusion, depth estimation, point clouds, inpainting, and upscaling. Essentially, you start with one of the following:
- An existing environment image
- A description of an environment
- An address of a real-world location
We then take the initial environment image, and using the techniques described below turn this into an environment that you can navigate with either your WASD keys or the buttons which appear on screen. Using the power of this rendering technique, we are able to use AI to ‘guess’ what the camera’s POV would be after performing various movements (-45° rotation, forward, 45° rotation). As the user moves throughout the environment, we keep track of these movements so we can maintain consistency throughout movements and also pre-render potential next frames to make the transitions appear near-real time.
How We Built It


DiffusionEarth was built using a combination of Python (API development, complex math pertaining to camera placement, point normalization, mask generation, etc.), Open3D (point cloud generation, camera movement, rendering, etc.), Stable Diffusion (Image generation, inpainting), Marigold (depth estimation), Moondream (image -> text), Creative Upscaler (upscaling), NextJS (frontend), TailwindCSS (styling), and the Google Maps API (street view imagery).
Here’s a rundown of everything that occurs in the process of generating and maintaining a DiffusionEarth generation:
- The start image is provided
- If the user provides an image, this is done
- If the user provides a prompt, a call is made to a turbo version of stable diffusion to generate the requested environment
- If the user provides an address, we use the Google Maps Street View API to get the starting image at that location
- We run the marigold depth estimation model on the image, which returns a depth map of the image.
- Using Open3D, we convert this combination to a group of points in 3D space forming an initial point cloud. Then, we create a grid of possible positions and orientations for a user to take in the 3D environment, and asynchronously render a view for each one. To do this for an unvisited view, we take the points in the field of view of the virtual camera closest to the view and estimate an average normal, which we transform the camera to look directly along. We then use the Nelder-Meade optimization method to analytically determine the optimum position along that vector to place the camera to minimize the amount of whitespace in the camera frame. With the initial perspective established, we can perform a small rotation or translation in the camera’s local frame to get an image close to the original but with slightly different perspective and fill in the revealed white space with an inpainting model. We then calculate the depth for that new image and use it as the basis for further unvisited views if the user continues to travel in that direction.
- We then perform the user’s requested action on the virtual camera, with the same FOV, leaving missing pixels in the new image.
- Then, the now moved camera’s output is rendered into a png
- Based on the rendered image and it’s now missing pixels, we generate a black & white mask to signal to Stable Diffusion which pixels should be painted.
- We also perform an image -> text description generation powered by Moondream, in order to provide greater context of the requested image to the impainting model.
- Then, the inpainting is performed, creating an updating version of the frame post-movement In the background, we kick off the following jobs:
- Upscaling: we generate a higher-quality version of the rendered point cloud which will replace the currently shown image once finished
- Pre-rendering: in parallel, we pre-render the 8 possible camera movements of each point, creating the effect of near real-time generation