September 17th, 2023
Video-based, Generative AI tutor w/ Complex Animations + Voiceover
1st Place | Microsoft AI Challenge @ FIU's Shellhacks Hackathon
Inspiration
Since we can remember, Khan Academy has been a source of learning and exploration for us as we've moved through elementary, middle, high school and now college. Whether it be math, science, history, or anything else we could also count on the website for highly visual and interactive, something that was invaluable for visual learners like ourselves.
However, due to the long-hours that creating each of these videos takes, it's hard for the Khan Academy team to create videos that are personalized to the learning needs of students when they need the information and impossible to create videos for the every problem or question a student might have.
This is where generative models like GPT-4 step in, students now have their own personal tutor available to them 24/7 365. However, these models are only able to generate text through interfaces like ChatGPT. Where does this leave students who are only really able to comprehend information when it is presented to them visually? The answer: disadvantaged compared to their classmates using these text-based models. That is... until now!!
Description
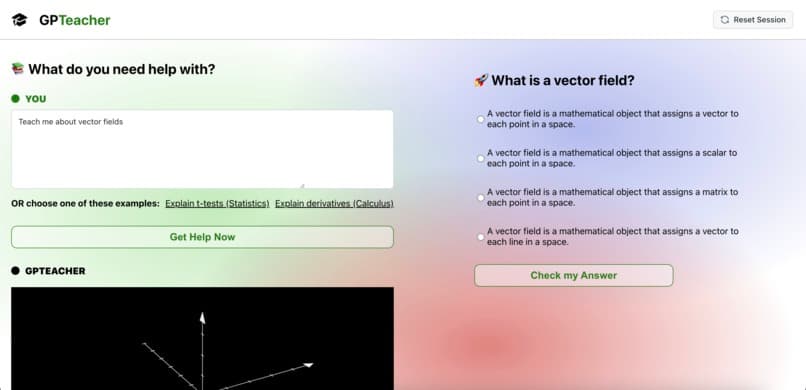
GPTeach is your complete video-based, generative AI tutor that can generate complex animations, 2D and 3D graphs, formulas, and so much more. The goal? Visually explain any topic to you, in addition to our TTS generation which explains the topic as well as explains what is going on in the visuals.
Additionally, along with generating these videos based on prompts or questions, GPTeach generates a question and a set of answer choices that allows you to test your learning from the video. Because we know that LLMs can hallucinate answers, we cross-reference the chosen answer choice with Wolfram Alpha to ensure it is correct. If the chosen answer is incorrect, GPTeach will generate an explanation of why it is wrong as well as a video visually presenting what is wrong in the user's logic and why the correct answer is the better option.
How We Built It
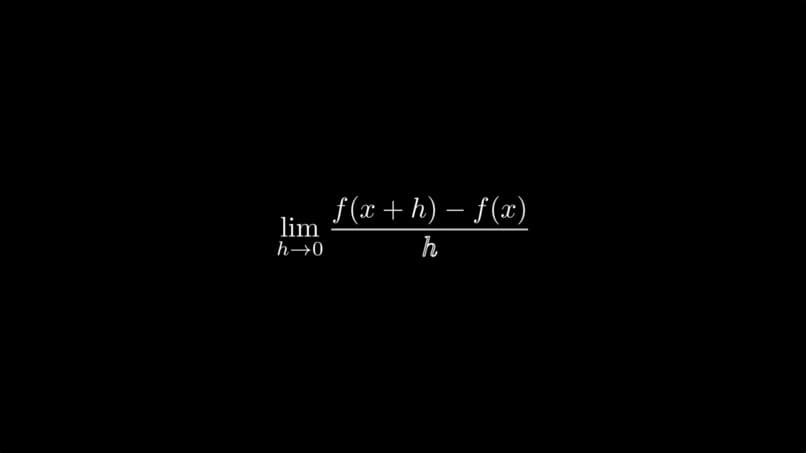
We built a GPT-4 agent that is in charge of orchestrating a storyboard of the video based on the user's prompt/question. We use a Pydantic-based output parser which forces the LLM to constrain it's output to a strict JSON format containing an array of visual and auditory prompts. We then use parallelized setup to execute Google Cloud TTS and a custom agent which generates Manim code. This custom GPT-4 agent utilizes a vector (Chroma) database which we created by scraping the documentation for Manim to run a similarity search to pull relavent documentation on generating the section of the video. The agent is then tasked with generating valid Manim code which we accomplish through a combination of various custom output parsers, which it uses to compile the animations and create the video snippets. From here, our code combines the visuals with the audio, time-matching them to ensure succinct and accurate explanations. At the end, we use ffmpeg to combine all of the video sections into one output file which we present in the web UI.
On the quiz-aspect of the site, we use GPT-4 to generate a quiz question related to the prompt, once again using custom Pydantic output parsers to ensure that the llm output is interpretable from the web UI. When a user selects an answer, a call is made to the Wolfram Alpha API with the quiz question, to ensure that an accurate evaluation of the user's answer can be made, which we then use the LLM to evaluate the similarities/differences between what Wolfram outputted to the user's selected answer choice.